Image Segmentation
Published:
Image segmentation is a sophisticated technique in computer vision that involves partitioning an image into distinct, meaningful regions. Its primary objective is to analyze and understand the visual content within an image by assigning specific labels to different parts of the scene. This process aids in extracting valuable information for various applications, such as object recognition, scene understanding, and autonomous navigation.
Types of Image Segmentation:
- Semantic Segmentation:
- Definition: Semantic segmentation entails the classification of each pixel in an image, assigning it to a predefined class. This approach offers a fine-grained understanding of the visual content by associating distinct labels with different objects or regions within the scene.
- Application: Ideal for tasks where a comprehensive understanding of object boundaries and categories is essential, such as in medical image analysis or scene parsing.
- Instance Segmentation:
- Definition: Building upon semantic segmentation, instance segmentation not only classifies pixels but also discriminates between individual instances of the same class. This means that each occurrence of an object is uniquely identified and labeled.
- Application: Particularly useful in scenarios where distinguishing between multiple instances of objects is crucial, such as in robotics, surveillance, or any application requiring precise object localization.
- Panoptic Segmentation:
- Definition: Panoptic segmentation is a holistic approach that combines elements of both semantic and instance segmentation. Its goal is to cover the entire scene by assigning a unique label to each pixel, whether it belongs to a “thing” (an object with a distinct instance) or “stuff” (background elements).
- Application: Offers a comprehensive understanding of the entire visual scene, making it beneficial for applications like autonomous driving, where recognizing both objects and the surrounding environment is vital.
These segmentation techniques play a pivotal role in advancing computer vision capabilities, enabling machines to perceive and interpret visual information with a level of sophistication akin to human understanding.
High-Level Architecture of Image Segmentation: Breaking it Down
In the realm of image segmentation, we follow a high-level architecture known as an encoder-decoder structure.
Encoder - Unveiling Features:
The encoder acts as a feature extractor, usually implemented with a Convolutional Neural Network (CNN). This part extracts features from the image, forming what we call a “feature map.” The initial layers focus on low-level features like lines, gradually aggregating them into more complex features like eyes and ears. This aggregation is facilitated by downsampling, akin to reducing pixel representation - like when your video chat gets a bit grainy but still allows you to recognize your friend through those key features.
Decoder - Crafting Predictions:
Now, let’s move to the decoder. Its role is to take these extracted features and generate the model’s output or prediction. Like the encoder, the decoder is also a convolutional neural network. It assigns intermediate class labels to each pixel in the downsized feature map. Then, it begins the intricate task of upsampling, gradually reintroducing the fine-grained details of the original image. This process continues until the image is restored to its original dimensions.
Final Touch - Pixel-Wise Labels:
The ultimate result is a pixel-wise labeled map. Each pixel is assigned a final class label, capturing the essence of what that pixel represents in the broader context of the image.
In simpler terms, think of the encoder as an investigator, diligently extracting clues (features) from the image. The decoder is the storyteller, piecing together these clues to reveal the complete narrative - pixel by pixel. This architecture, with its encoder and decoder dance, forms the backbone of image segmentation algorithms, providing us with detailed, pixel-level insights into visual data.
Popular Architectures for Image Segmentation
Fully Convolutional Neural Networks (FCN):
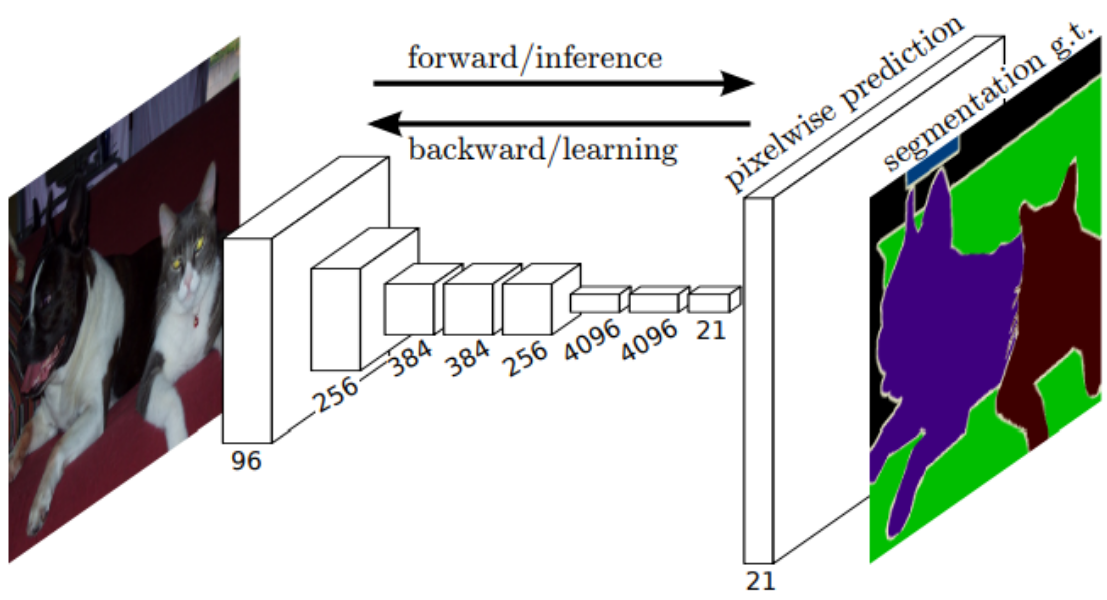
- Definition: FCNs are neural networks designed for semantic segmentation. The key innovation is replacing fully-connected layers with convolutional layers acting as both encoder and decoder. Encoder layers detect features and downscale the image, while the decoder layers upscale the image, creating a pixel-wise labeled map.
- Encoder: Feature extractors, such as VGG16, ResNet 50, or MobileNet, are used in the encoder part. These layers can be pre-trained and reused.
- Decoder: The decoder is denoted as FCN-32, FCN-16, or FCN-8, indicating the stride size during upsampling. Smaller stride sizes result in more detailed processing.
Stride in Convolutional Layer:
- Definition: Stride determines how many pixels the sliding window shifts as it traverses the image during convolution. Smaller strides lead to more detailed processing.
SegNet:
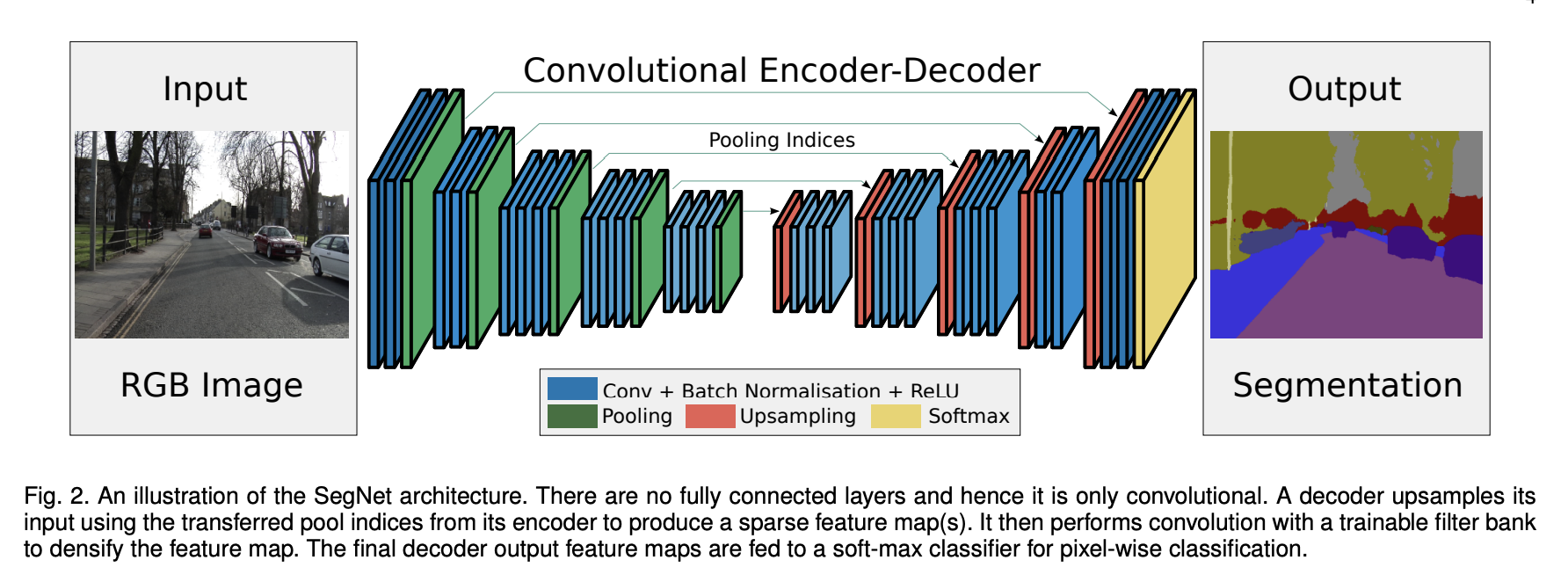
- Definition: SegNet is a network for image segmentation similar to FCN but with symmetric encoder and decoder layers. Each pooling layer in the encoder has a corresponding upsampling layer in the decoder, creating a mirrored structure.
U-Net:
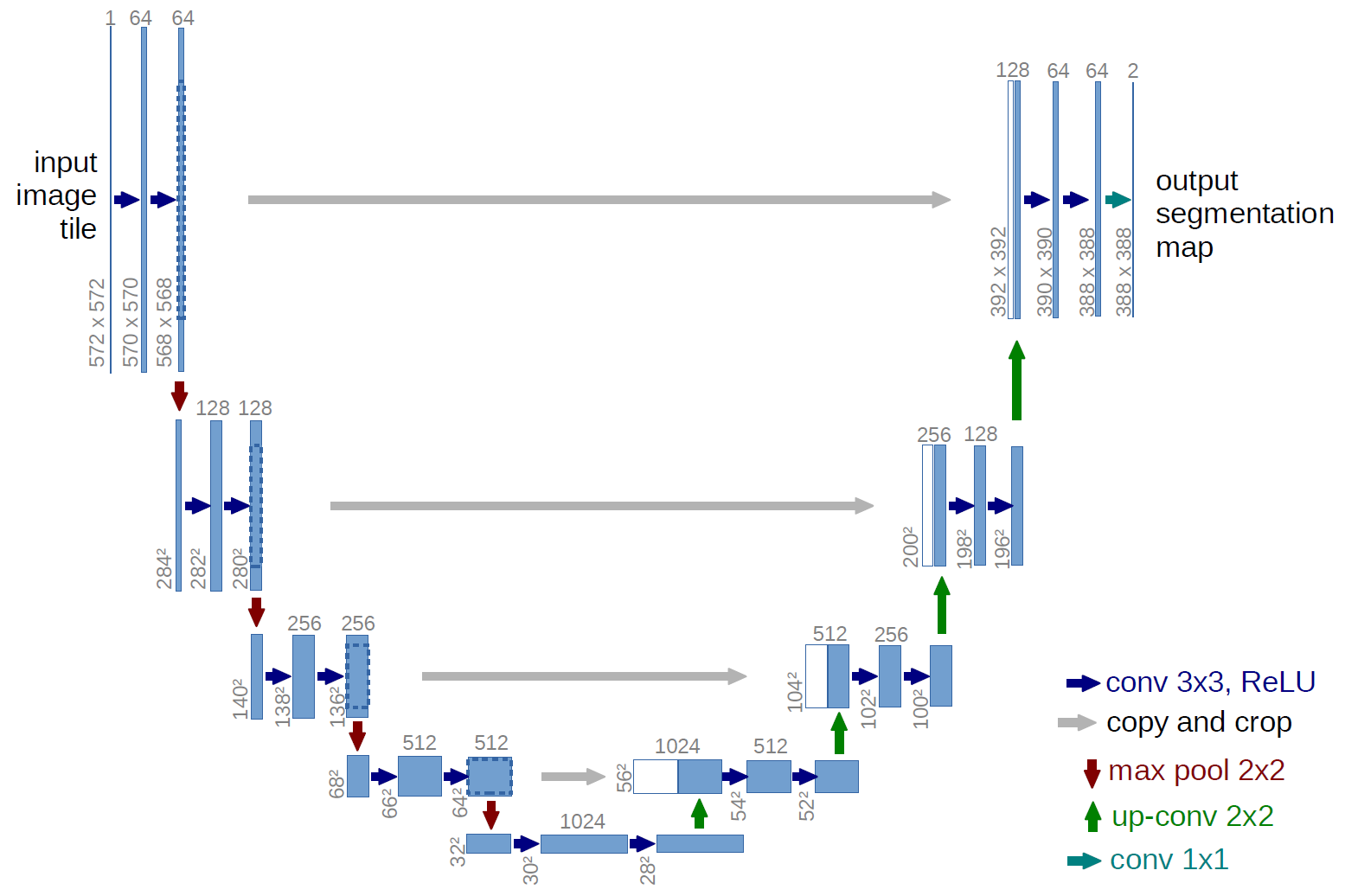
- Definition: U-Net is another architecture for semantic segmentation with a symmetric design. It has an equal number of stages for upsampling and downsampling. The name “U-Net” reflects the architecture’s U-shaped structure.
Mask R-CNN:
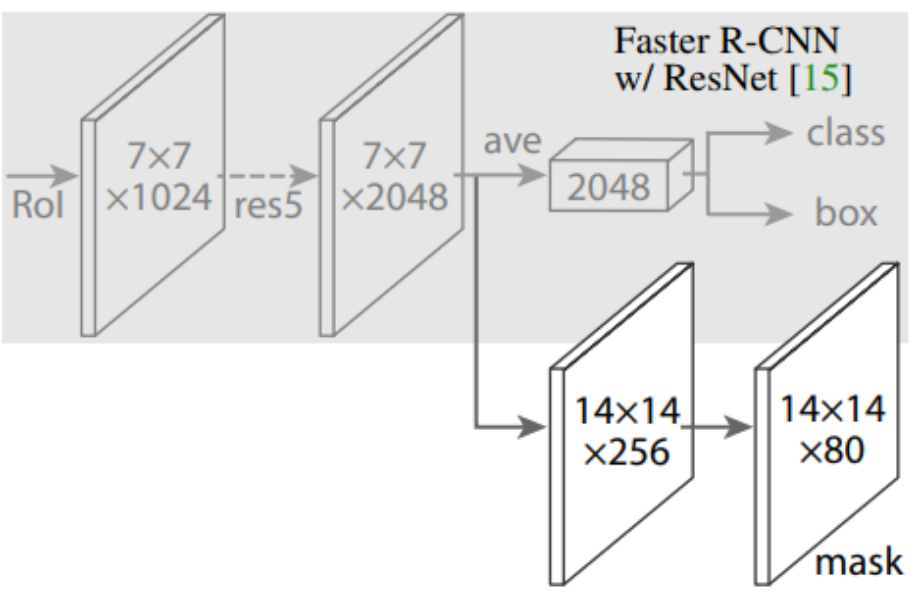
- Definition: Mask R-CNN is an architecture for instance segmentation, building upon Faster R-CNN used in object detection. It adds an additional branch for upsampling after feature extraction to produce pixel-wise segmentation masks, transforming the object detection model into an image segmentation model.